Method
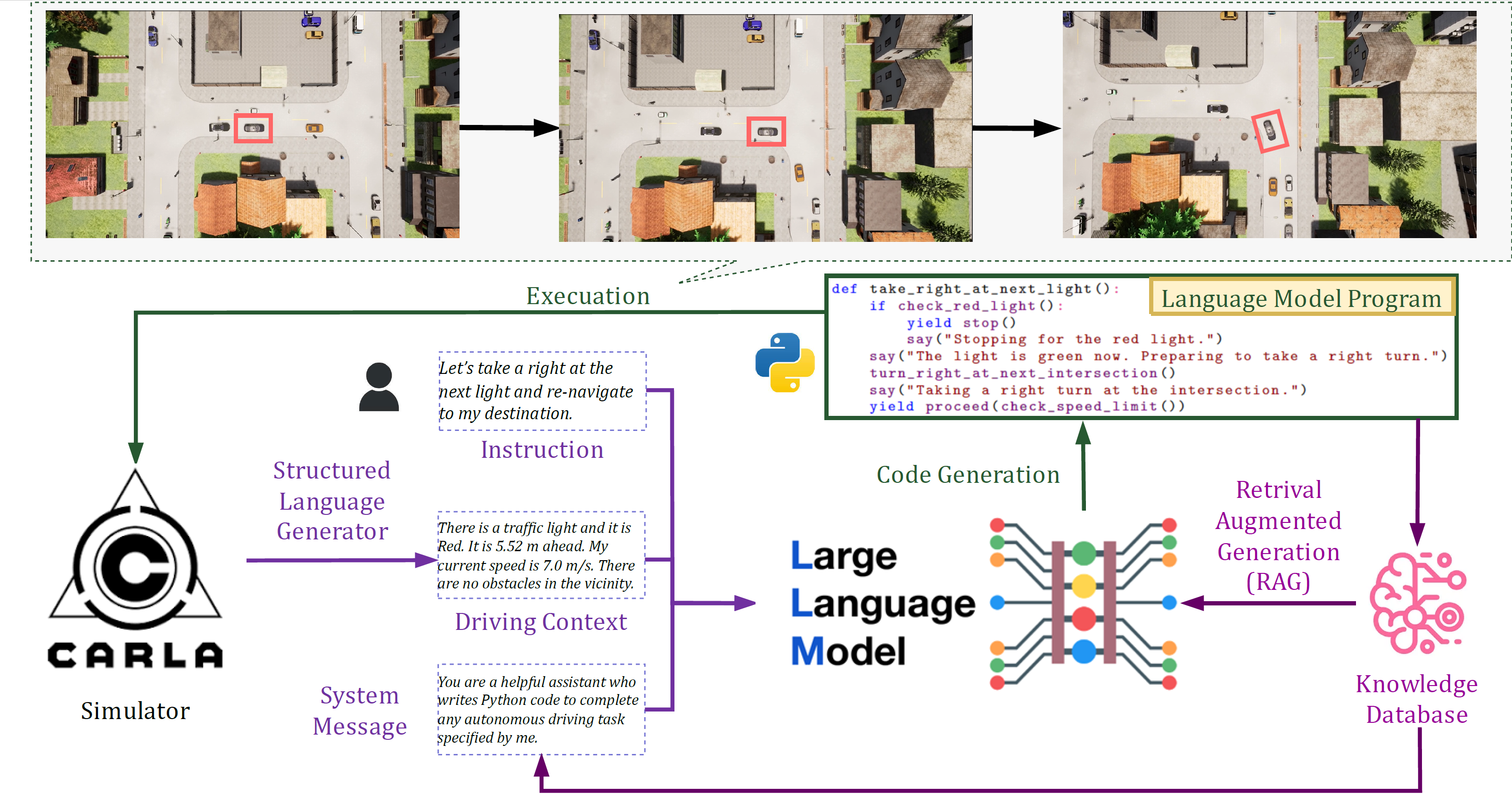
Traditional autonomous driving systems have mainly focused on making driving decisions without human interaction, overlooking human-like decision-making and human preference required in complex traffic scenarios. To bridge this gap, we introduce a novel framework leveraging Large Language Models (LLMs) for learning human-centered driving decisions from diverse simulation scenarios and environments that incorporate human feedback. Our contributions include a GPT-4-based programming planner that integrates seamlessly with the existing CARLA simulator to understand traffic scenes and react to human instructions. Specifically, we build a human-guided learning pipeline that incorporates human driver feedback directly into the learning process and stores optimal driving programming policy using Retrieval Augmented Generation (RAG). Impressively, our programming planner, with only 50 saved code snippets, can match the performance of baseline extensively trained reinforcement learning (RL) models. Our paper highlights the potential of an LLM-powered shared-autonomy system, pushing the frontier of autonomous driving system development to be more interactive and intuitive.

@inproceedings{ma_learning_2024,
title = {Learning {Autonomous} {Driving} {Tasks} via {Human} {Feedback} with {Large} {Language} {Models}},
booktitle = {{EMNLP} {Findings}},
author = {Ma, Yunsheng and Cao, Xu and Ye, Wenqian and Cui, Can and Mei, Kai and Wang, Ziran},
year = {2024},
}